Virtual Tourist Guide
A voice assistant in autonomous vehicles to help people arrange their travels in new cities.
ROLE - Conversational Interaction Designer
● Led the design of conversation flow
● Conduct several rounds of user testing
● Defined intents, utterances, and slots
TEAM & TIMELINE
Carol Jiang, one month
TOOLS
Figma, Sketch, Lucidchart, VoiceFlow, Illustrator, iMovie, Audacity


Over the years, many car functions have become automated. Recent advances have led to automation of the main driving task. We think that even if there’s a long road ahead, self-driving car is increasingly shape the mobility of the future. We want to explore the future possible usages of self-driving car and how the voice assistant can help to bring better user experiences on the road.


What is this magnificent building I’m passing by?
Where can I find some New York exclusive coffee shops?
Where should I go now?
…
While traveling, countless questions will come up that need to be answered or solved as fast as possible. Our goal is to design a voice assistant that can help solve these problems.


A Design Question Emerges…



01. First time designing within autonomous vehicle
Challenge
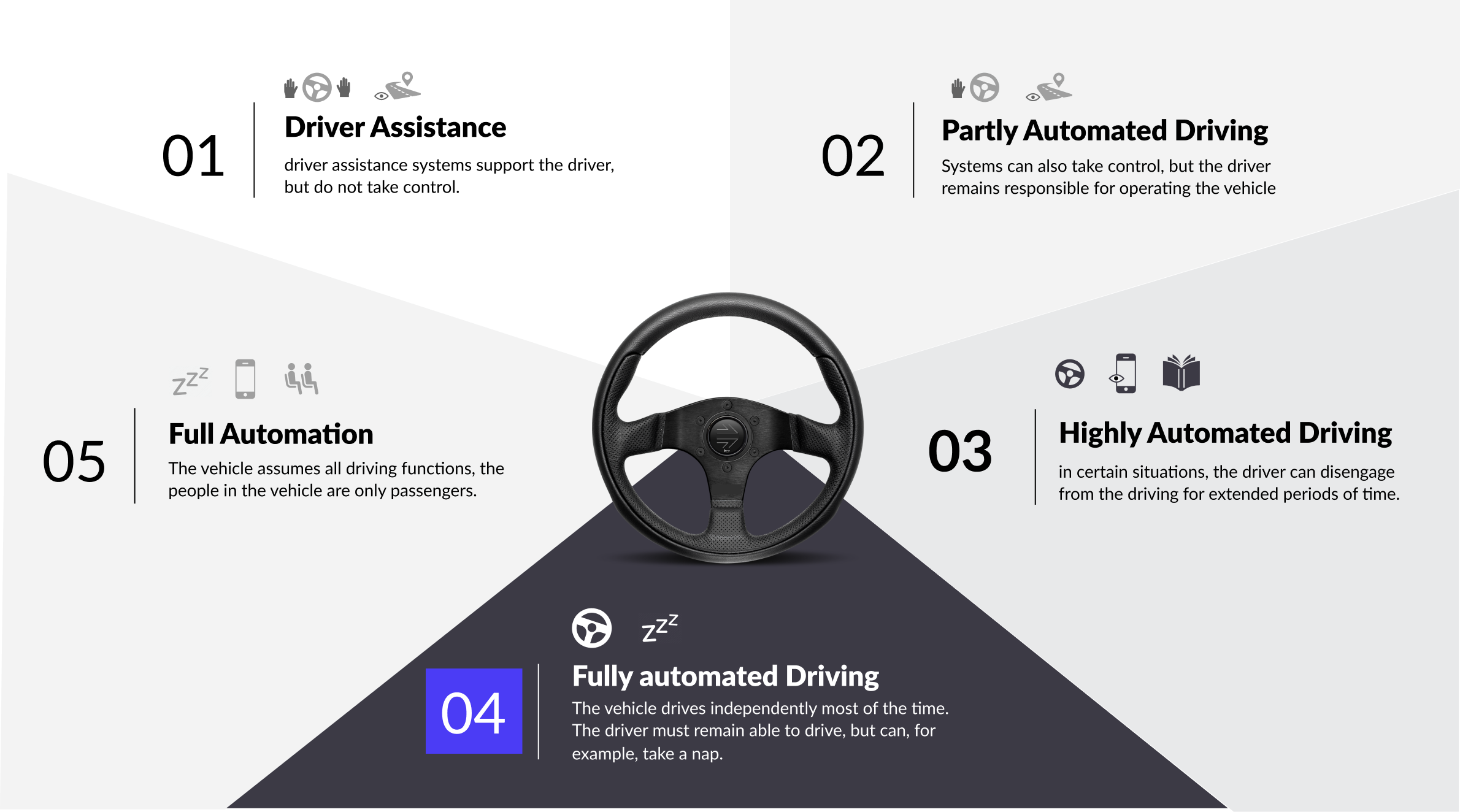
Experts have defined five levels in the evolution of autonomous driving. Each level describes the extent to which a car takes over tasks and responsibilities from its driver, and how the car and driver interact. However, it is our first time to design within autonomous vehicles. Which level should we choose?
Design decision
After interviewing experts in the field of autonomous driving, we found that there are many serious constraints such as regulations, laws, and insurance, lies in getting from level 2 to level 3. Humans have to be ready to take over, yet carmakers aren’t particularly confident in their ability to do so at a millisecond’s notice. As a result, for this project, we are trying to innovate by jumping to Level 4 autonomy, where no driver involvement is necessary in almost all cases.
02. Building trust is an important concern for autonomous vehicles
Challenge
In order to bring users a better experience, we struggled at the beginning and found it hard to decide the main interaction modal. At first sight, visual interactions made more sense since they are more intuitive & familiar with users and auto-driving vehicles provided users with time and energy to distract from driving. However, after further research, we realized that “lacking of trust on vehicles”, as a key concern in In car monitoring driving environment, was hard to be mitigated by visual interactions. How could we balance multimodal interaction?
Design decision
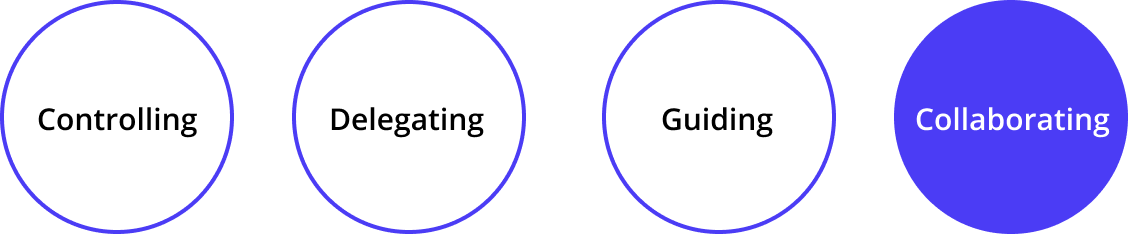
Through literature review and interviewing academic experts, we found that in-car voice assistants had the chance to play unprecedented roles in building trust between human and cars. As a result, we decided to move the main modal from visual to voice design. Moreover, we consulted with academic expert Paul Pangaro and got inspirations from his four modes theory. Collaboration mode, one of the four modes, could be the key to build trust between users and cars.

01. Identify the purpose and capability
Based on 10+ literature reviews and 3 rounds of users testing, we brainstormed the main purpose and scoped down the capability of our virtual tour guide. We explored three basic patterns to generalize all potential scenarios in the process.

02. Who is our user?
Interviewing people from various ages and industries, we realized that people have various requirements for voice assistants and held different opinions on autonomous cars. In order to maximize the capabilities of our voice assistant, we selected a young person who loves traveling and is willing to experience the latest technology as our final persona.

03. What does she experience?
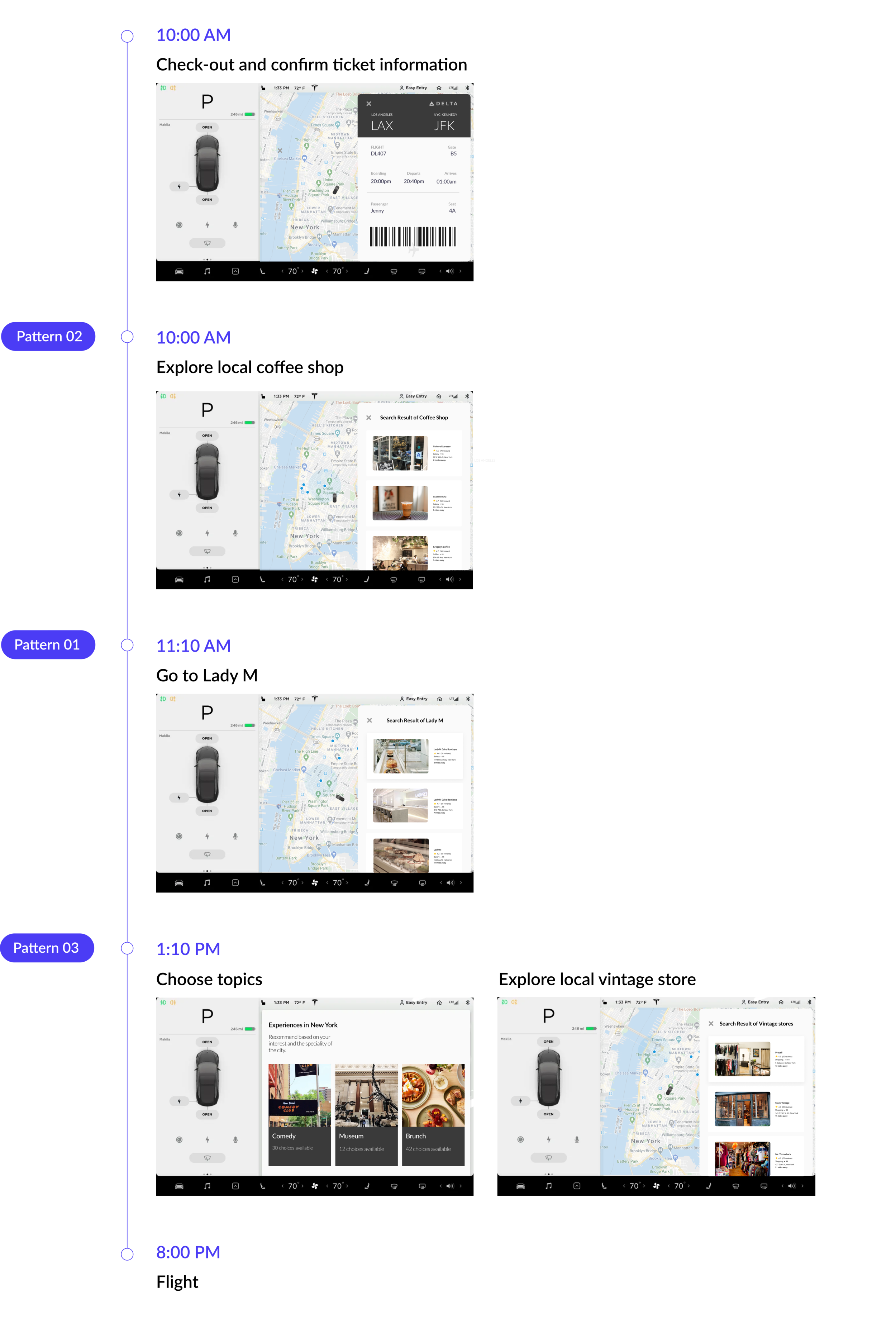
This was Jenny’s last day staying in New York for the the spring break and her flight back to Los Angeles is 20:00 PM at JFK airport. Jenny checked out of the hotel at 10:00 AM and rented an autonomous vehicle from the hotel front-desk. She wanted to go to a Lady M and buy a birthday cake for her friends. However, Lady M wasn’t open until 11:00 AM and thus the voice assistant recommended a coffee shop for her to have some brunch first. After buying the cake, there’re still plenty of time and Jenny didn’t have a solid plan so she ask the voice assistant for recommendations and Jenny picked several vintage stores.
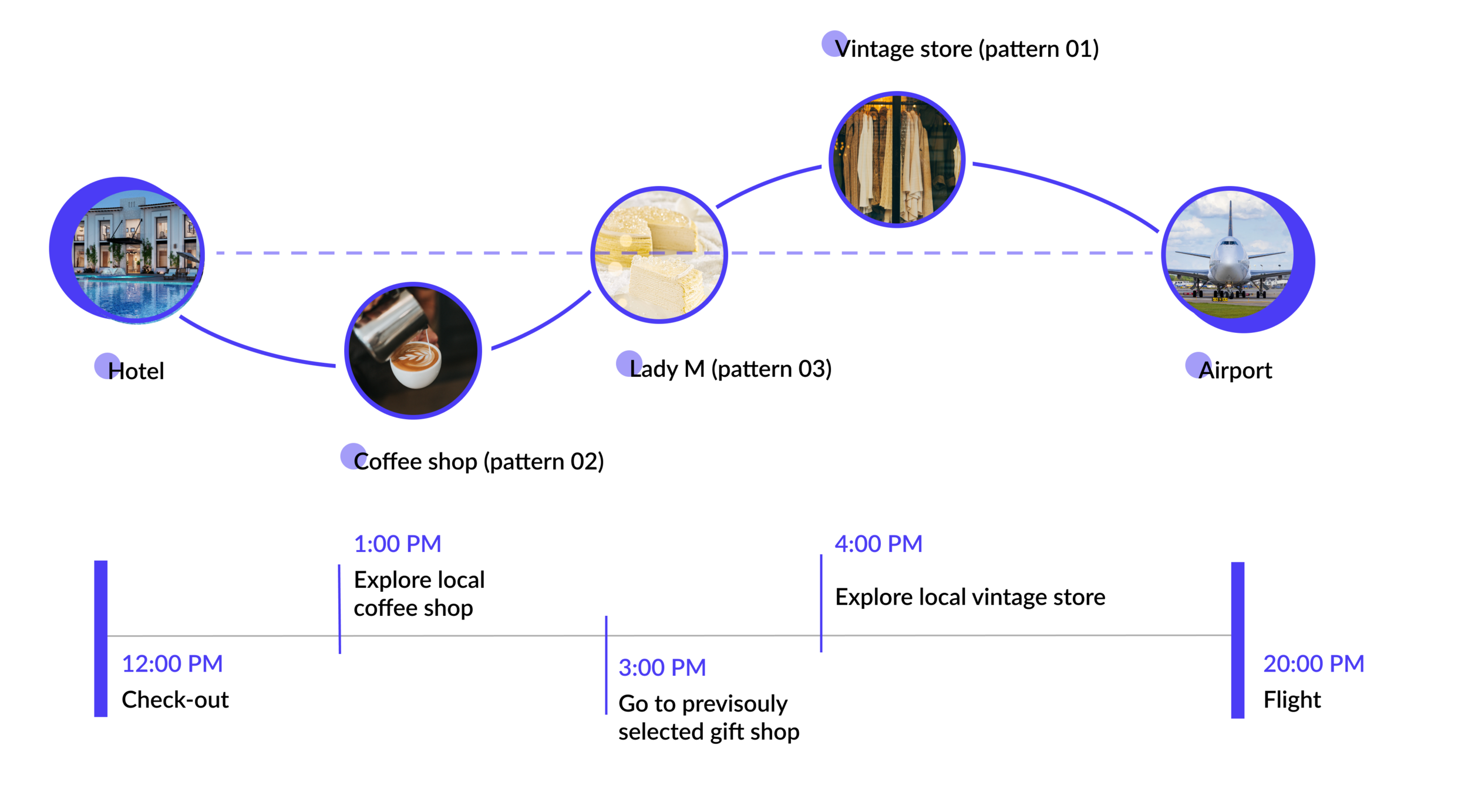

Preliminary Flow
Now that we had a clear picture of who’s communicating and what they’re communicating about, we started writing sample dialogs. We were looking for a quick, low-fidelity sense of the “sound-and-feel” of the interaction we’re designing. We conducted role-playing with 3+ people to create the initial script.
First Iteration: improve the logic of the flow

Finding: In interviews, users jumped into the middle of the flow directly. (e.g. users directly tell the CUI “I want to explore some coffee shops)
Design decision: We thought about potential starting points users may jump into and added that to our flow.Here is an example and click here to view the whole picture.

Findings: Users expect the CUI to remember some important information after each round of conversation.
Design decision: We then asked ourselves “what kind of information our CUI need to remember”. We figured out that the final destination and time to arrive at the final destination is important to users and it will be great if CUI can keep those information in mind during the journey.

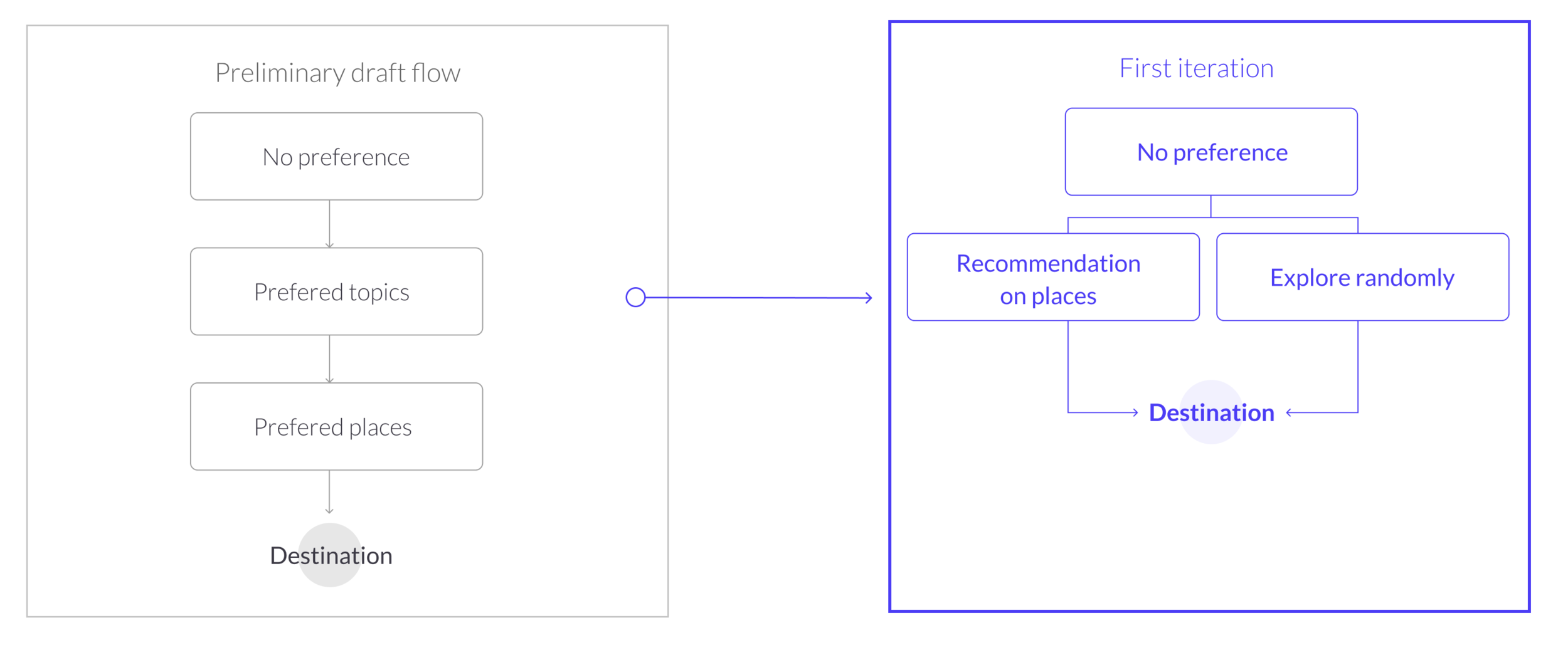
Findings: In the preliminary draft, we sequenced the three patterns to help them narrowing down scopes and found a destination. However, after several interviews, we realized that, instead of narrowing down step by step, it’s better to give out some recommendations or just randomly exploring the city.
Design decision: In the iteration, we redesigned the flow of the pattern that users don’t have preferences. We provided straightforward recommendations and also create a choice called “random exploration” to help narrow down their choice without compromising their active exploration.
Second Iteration: make the conversation more human-like

Findings: Consulting with academic experts and conducting literature review, we realized that human beings combine different modes in conversation and shifting among different modes when they talk.
Design decision: We segmented the flow into smaller sections and re-thought about each section of the conversation with specific modes according to their goals and means.

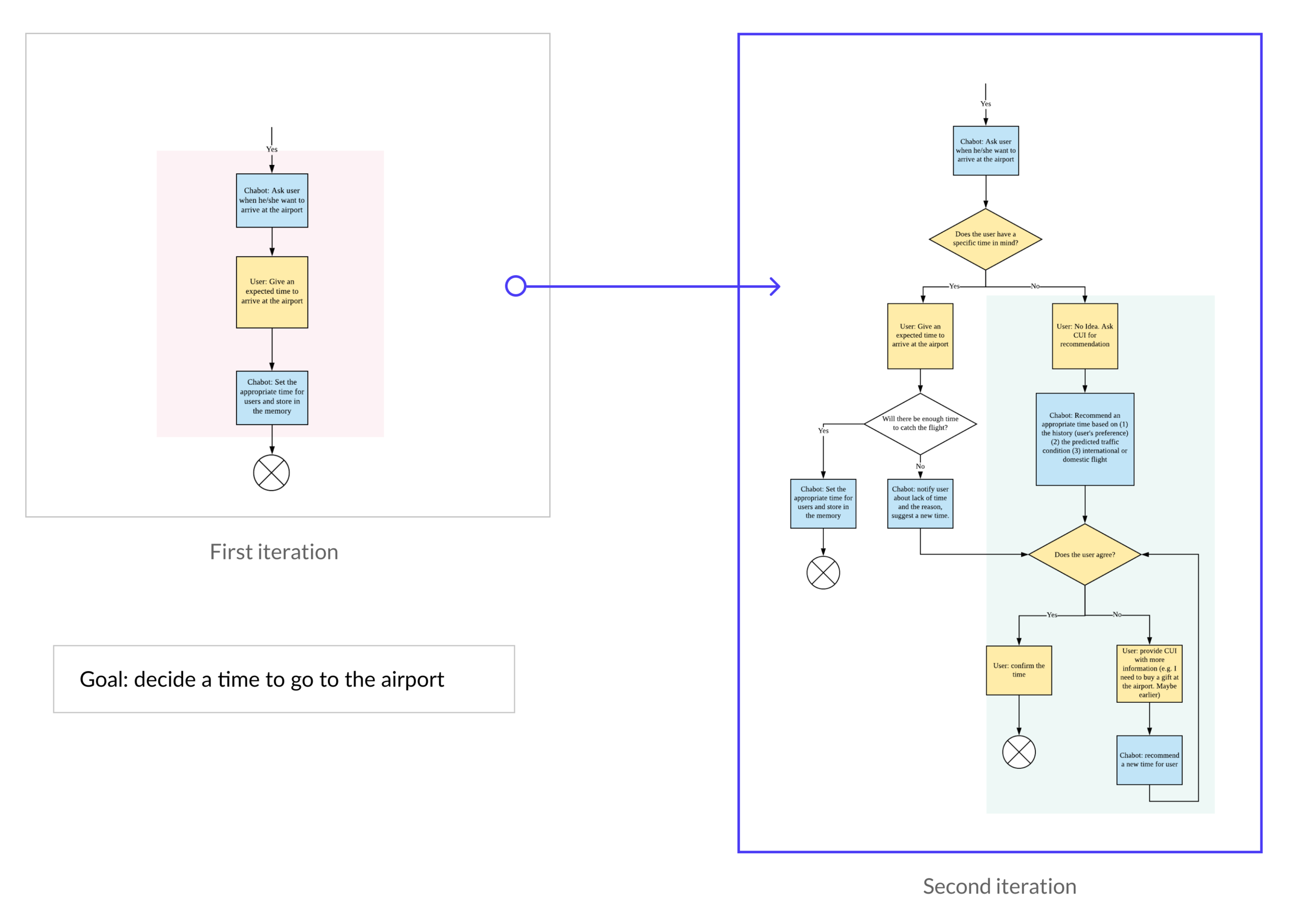
Findings: In collaborating mode, users and voice assistants would work together to define a goal for users. For example, users would like to set a time to go to the airport. In traditional controlling modes, voice assistants would follow what users say. However, if voice assistants are able to suggest a better time for users, and also discuss with users together to settle the time, users would begin to build some trust on assistants.
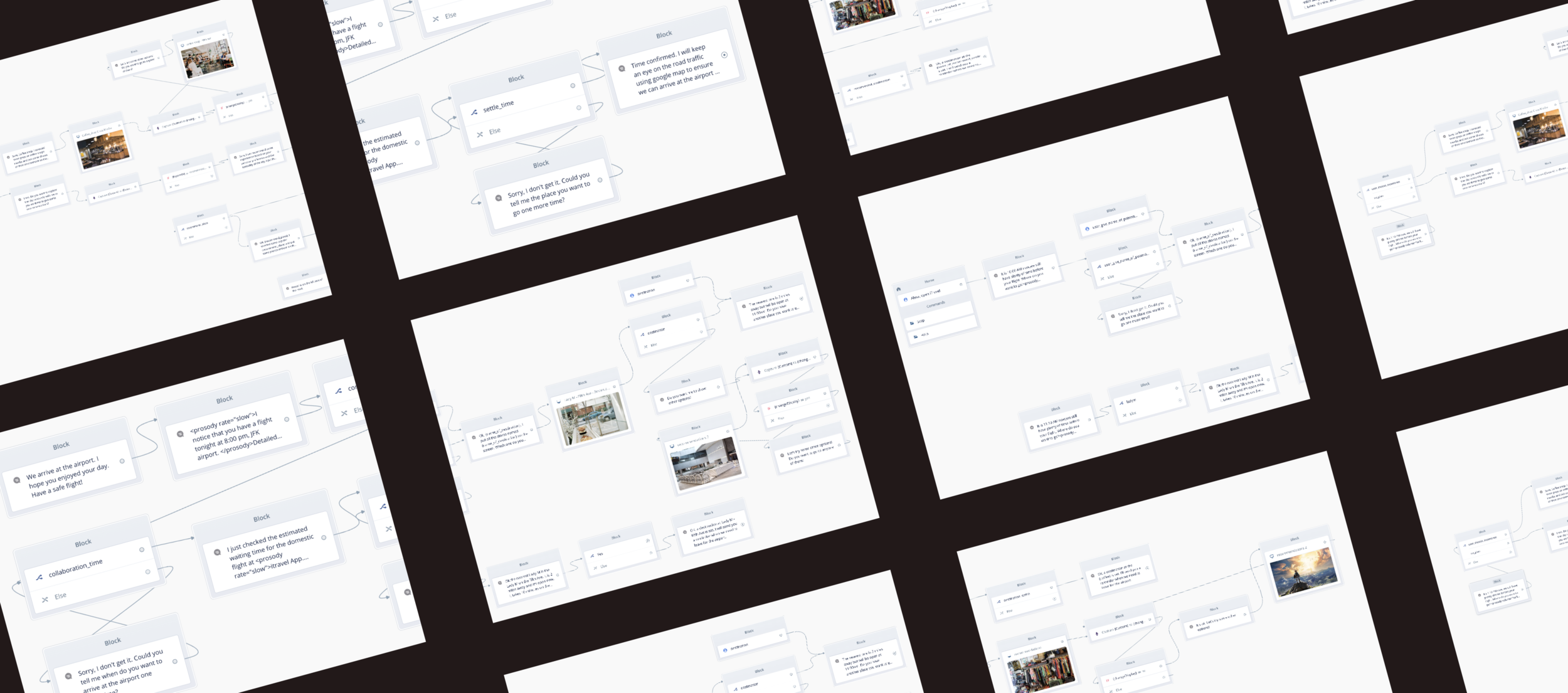
Design decision: After consulting with academic experts, we redesigned three main parts of the flow and modified them into more collaborating modes. Here is an example of setting time to go to the airport. The whole flow can be referred here.

Guided by the finalized conversation flow, we rewrote the sample dialogs into a more detailed script. After that, we annotated each sentence users may say and the voice assistant may answer by identifying the utterances, indentation, entity, and slots in each turn. (click to enlarge the pictures)
*We implemented it in VoiceFlow:


We designed the interface based on Tesla Model 3’s 15-inch screen.